Architektura procesorů Nehalem (2/2)

Seznam kapitol
Nehalem bude první masově nasazovaný procesor Intelu, který bude integrovat řadič pamětí blízko procesoru. Tím ale výčet novinek nekončí. Inženýři se při návrhu zaměřili také na návrh samotné výpočetní části a kompletně předělali také návrh cache subsystému. Pojďme se podívat, v čem budou největší změny samotné architektury procesoru.
První část článku najdete zde.
V tomto článku navážeme na povídání o nových platformách a zaměříme se na samotný procesor.

Celková koncepce procesoru Nehalem vychází z osvědčené architektury Core, na níž jsou založené všechny x86 procesory Intelu z poslední doby a která se sama v mnohém inspirovala u Pentia Pro z roku 1995. Nehalem tedy není úplně nový procesor a podle aktuálně dostupných zpráv to vypadá, že rozdíl mezi ním a Core bude asi takový jako mezi Athlonem XP a Athlonem 64 – tedy v některých ohledech zásadní změny, jinde spíše malá vylepšení, ale v žádném případě ne velká rizika v podobě zcela nových přístupů.
Základní rysy Nehalemu jsou následující:
- Out-of-order vykonávání instrukcí.
- 4-issue superskalární architektura se 128 in-flight microOPs.
- Dvě současně zpracovávaná vlákna na jádro (Hyper-Threading).
- Standardní koncept datové a x86 instrukční cache.
- 64bit ALU jednotky.
- 16 stupňů pipeline.
Většinu z těchto vymožeností již obsahovala architektura Core. Hlavními novinkami jsou především delší pipeline (patrně jako důsledek většího fyzického rozměru jádra), schopnost zpracovávat současně dvě vlákna v jednom jádře a rozšířené zdroje procesoru (zejména rozšířené instrukční okno na 128 microOPs).
Front-end
První část procesoru sestává ze získávání instrukcí (fetch) a jejich dekódování. Nehalem pracuje, stejně jako všechny moderní procesory, s vnitřními microOPs instrukcemi, tedy jakýmisi jednoduchými operacemi, které umí jeho výpočetní jednotky přímo zpracovat. Instrukce zadané programátorem (tedy sada x86 a jí rozšiřující sady) jsou na tyto instrukce převáděny (dekódovány). Procesor tedy nepracuje přímo s x86 instrukcemi (tzv. macroOPs), ale jejich ekvivalenty microOPs, přičemž jedna x86 instrukce je rozdělena na jednu nebo více microOPs, dle složitosti.
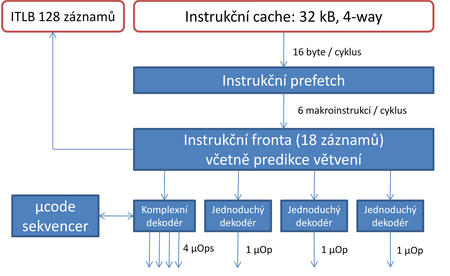
Instrukce přichází do pipeline z instrukční cache. Ta má velikost 32 kB, stejně jako u Core. Oproti Core je tato cache ale v jedné věci pozměněna - v důsledku přítomnosti Hyper-Threadingu je nově konkurenčně sdílená a dvouportová (umožňuje přístup dvěma logickým procesorům, které se dělí o kapacitu na základě vytížení). Protože návrh takové cache je složitější, tedy obecně taková cache je při stejných parametrech nutně pomalejší, byla zvolena strategie, kdy tato cache je pouze čtyřcestná a nikoli osmicestná jako u Core. To snižuje její účinnost (hit-rate). Přesto se to zdá být nejlepší řešení, neboť zmenšení velikosti nebo zvýšení latence by mělo horší důsledky.
V tomto ohledu je zajímavé srovnání s přístupem, který aplikuje AMD. To zvolilo cestu velké (64 kB) instrukční cache s identickou latencí jako Intel (3T), ale pouze 2-way asociativitou. Je otázkou, který z těchto přístupů obecně programům vyhovuje více.
Z cache instrukce putují tempem až 16 bytů za cyklus do 16 bytů velkého zásobníku, ve kterém probíhá prvotní předdekódování – rozdělení datového bloku na instrukce. Následně se pak instrukce tempem až 6 za cyklus přesouvají do fronty k dekódování. Fronta má kapacitu 18 instrukcí a její součástí je predikce větvení kódu, nezbytná součást každého out-of-order mikroprocesoru. V této oblasti by měl Nehalem přinést zlepšení, neboť jeho prediktor byl dále vylepšen, zejména s ohledem na aplikace, které pracují s rozsáhlými algoritmy (např. databázové servery). Zároveň prediktor nyní podporuje Hyper-Threading a měl by zachovávat funkčnost všech dříve používaných funkcí, tedy zejména prediktoru ukončení programových cyklů a prediktoru skoků s neznámým cílem (nepřímých skoků - indirect branch):
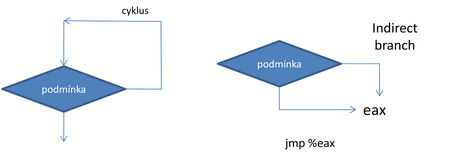
Předpovídané adresy instrukčního pointeru jsou hledány v instrukčním Translation Look-Aside Bufferu, který obsahuje 128 záznamů pro 4 kByte stránky (sdílené pro obě vlákna) a 7 záznamů pro 2 a 4 MByte stránky (unikátní pro každé vlákno). Kapacita ITLB i jeho asociativita (4-way) zůstaly stejné jako u Core.